LLM(大規模言語モデル)とは? ChatGPTなどのAIとの違い、仕組みを解説

近年ではさまざまな生成AIサービスが登場しており、今や生成AIは個人での利用にとどまらず、あらゆるビジネスシーンで活用されています。特にChatGPTをはじめとしたテキスト生成系のAIサービスは、普段の生活の中で利用している方も多いのではないでしょうか。これらテキスト生成系AIの根幹を担っているのが、LLM(大規模言語モデル)と呼ばれるAIモデルです。今回はLLMについて、その概要や仕組み、活用事例などを詳しくご紹介します。
LLM(大規模言語モデル)とは何か
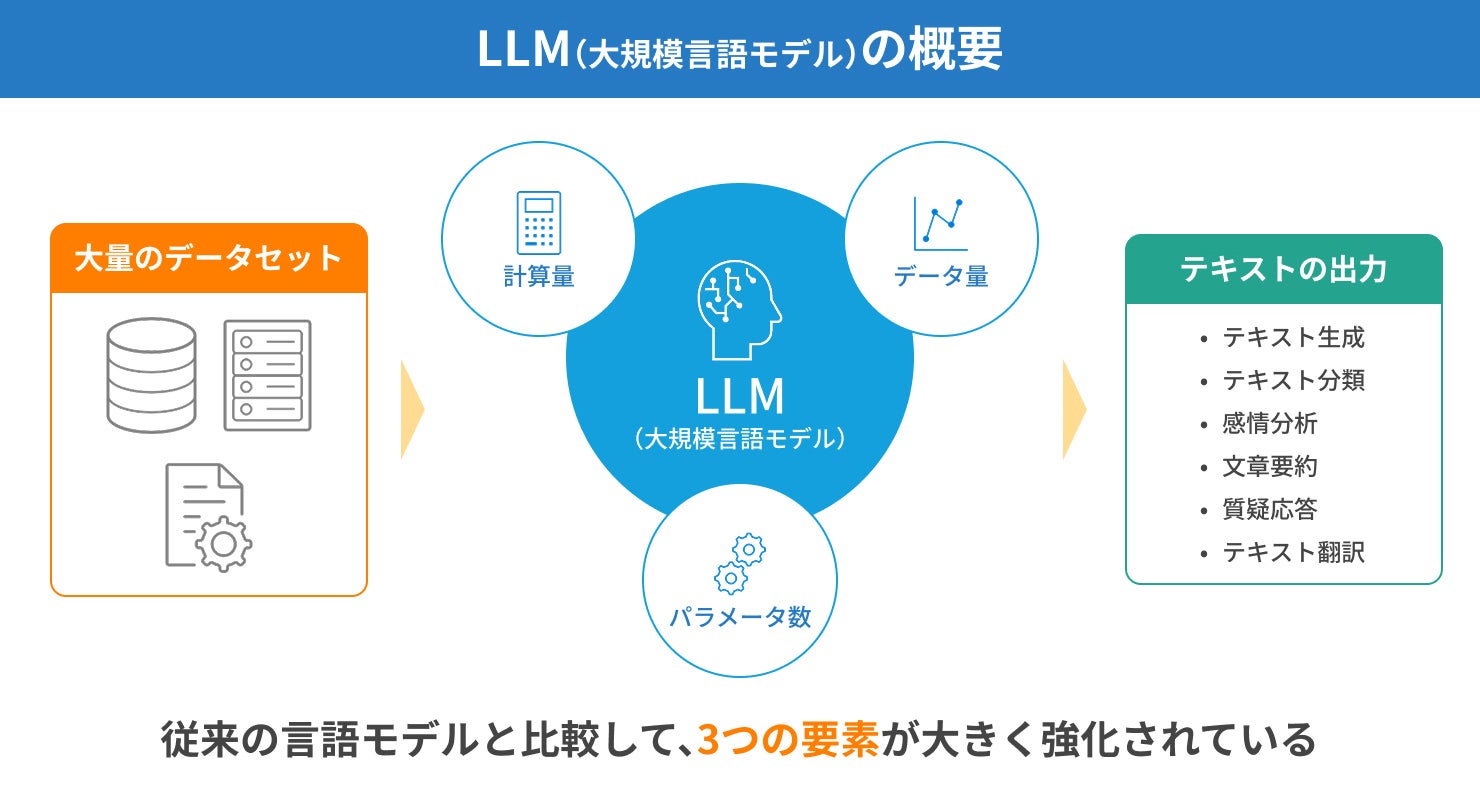
LLM(大規模言語モデル)とは、膨大なデータセットとディープラーニングによって構築されたAIモデルです。自然言語処理に特化したモデルであり、テキストの生成をはじめ、あらゆる場面で活用されています。また、LLMという言葉自体は「Large Language Model」の略称です。
LLMは、従来の言語モデルと比較して、「計算量(コンピューターが処理する仕事量)」「データ量(入力された情報量)」「パラメータ数(機械学習モデルが学習中に最適化する変数の数)」が大きく強化されています。これらに加えてファインチューニングを行うことで、文章生成、テキスト要約、質疑応答といったさまざまな自然言語処理を高精度で行うことが可能です。
代表的なLLMには、OpenAI社の「GPT」やGoogle社の「BERT」、Meta社の「Llama」などがあります。
言語モデルとは何か
そもそも言語モデルとは、言葉や文章を元に、人間の言語を単語の出現確率を用いてモデル化したものです。
言語モデルでは大量のテキストデータを学習し、ある単語の後ろにはどの単語が続きやすいのかなど、各単語の出現する確率を分析していきます。たとえば、「私の好きな食べ物は」に続く単語として、「カレーライス」「ハンバーグ」「和食」などは出現確率が高く、「サッカー」「海」「黄色」などは出現確率が低いといった具合です。
このように言語モデルはあらゆる単語の出現確率を統計的に分析し、言語をモデル化することで、より違和感のないテキストの出力や、人間が入力した文章の理解ができるようになります。
ファインチューニングとは何か
ファインチューニングとは、機械学習の分野において、事前学習済みのモデルの一部または全部に対して再トレーニングを行い、パラメータの微調整をすることです。
LLMのファインチューニングでは、すでに大規模なデータセットによるトレーニングを行ったモデルに対し、ニューラルネットワークのパラメータを調整することで、新しいデータへの対応力を高めていきます。
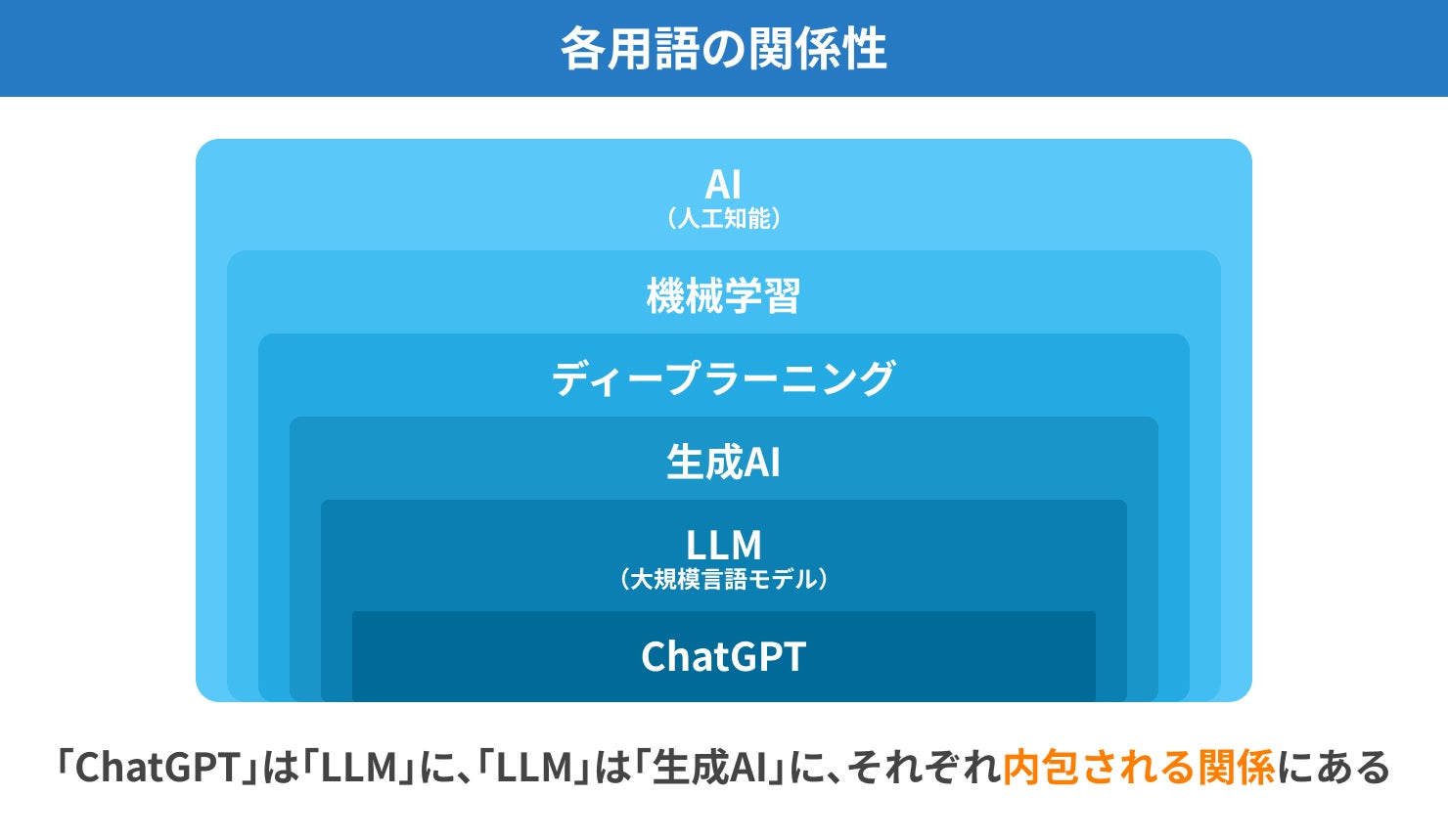
LLM(大規模言語モデル)と生成AIやChatGPTは何が違うのか
LLM(大規模言語モデル)とよく一緒に語られるものに「生成AI」や「ChatGPT」があります。これらは非常に似ているため混同されることも多いですが、厳密には異なります。ここでは、それぞれの違いについてご紹介します。
LLMと生成AIの違い
LLMと生成AIはどちらもAIですが、得意分野の広さに違いがあります。生成AIはテキストや画像、動画、音声などのさまざまなコンテンツを自ら生み出すことができるAI技術の総称です。
一方で、LLMは「生成AIの一種」であり、テキストデータの生成など、自然言語処理に特化したAIモデルです。ほかの生成AIのように画像や動画、音声などは生成できません。つまりLLMは、生成AIという大きなカテゴリに内包された、テキスト生成特化型のモデルであるといえます。生成AIについての詳細は以下に記載しています。

LLMとChatGPTの違い
上記の通り、LLMは自然言語処理に特化したAIモデルで、生成AIというカテゴリに位置する技術の一つとして捉えることができます。一方でChatGPTは、OpenAI社 がLLMの技術を活用して開発した、対話型のテキスト生成系AIサービスの名称です。つまり、ChatGPTはLLMの活用事例の一つといえます。
また、LLMは特定の条件やパラメータに基づいて文章を生成しますが、ChatGPTはそれに加えて、まるで人間と会話しているような流ちょうで自然な文章を生成することが可能です。
LLM(大規模言語モデル)における言語処理の流れ
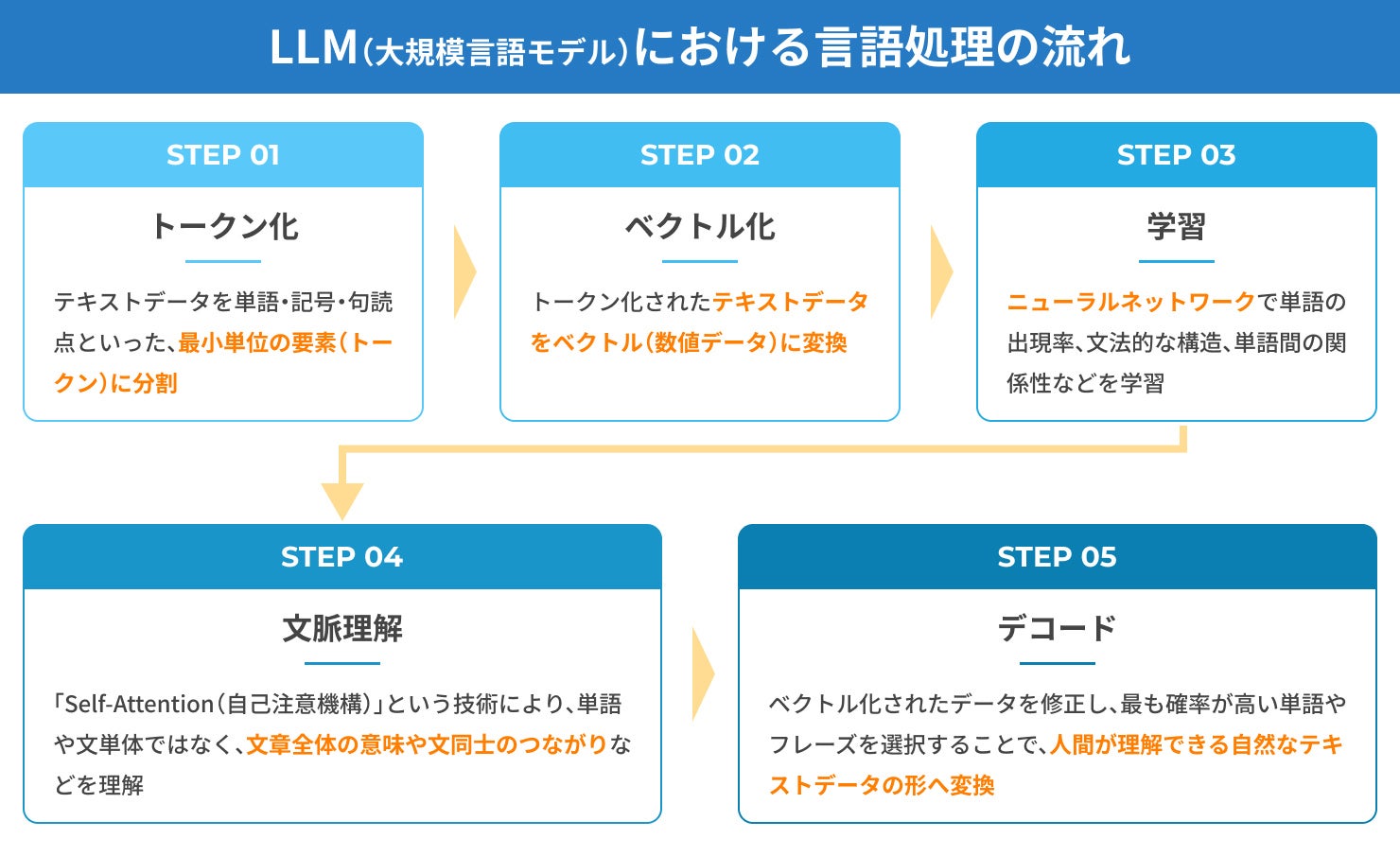
ここまでLLM(大規模言語モデル)の概要をご紹介してきましたが、実際にLLMはどのような仕組みで機能しているのでしょうか。ここでは少し掘り下げて、LLMにおける言語処理の流れについて解説します。
トークン化する
最初に、LLMでは入力されたテキストデータを単語・記号・句読点といった、テキストの中で意味を持つ最小単位の要素(トークン)に分割していきます。たとえば、「私はサッカーが好きです。」という文があった場合、「私」「は」「サッカー」「が」「好き」「です」「。」といった具合に分割されます。この処理をトークン化といい、LLMが自然言語を理解し、処理するために非常に重要なステップです。
また、言語によってトークン化の処理は異なります。英語のような単語と単語の間にスペースが存在する言語はシンプルに分割できますが、日本語のように明確なスペースが存在しない言語ではトークン化のプロセスはより複雑になります。
ベクトル化する
コンピューターはテキストデータをそのまま理解できないため、前のステップでトークン化されたテキストデータをベクトル(数値データ)に変換する必要があります。ベクトル化することでテキストが数値に変換され、コンピューターがテキストデータを認識し、情報として解析することが可能です。
また、ベクトル化によって各単語の関係性や意味の類似性も計算できるようになり、同義語や関連性の高い単語はベクトル上で近い位置に表現されます。これにより、次のステップとなるニューラルネットワークによる学習の精度が向上し、より自然な文章生成へとつながります。
ニューラルネットワークを用いた学習をする
ベクトル化されたテキストデータは、続いてニューラルネットワークに入力されます。ニューラルネットワークは、「入力層」「隠れ層(中間層)」「出力層」といった複数の層で構成されており、LLMの核となる部分です。隠れ層が多いほどより複雑なデータの解析が可能で、各層を通過するたびに異なる特徴を抽出しながらデータを処理していきます。
この過程を通してLLMは、単語の出現率、文法的な構造、単語間の関係性などを学習していきます。これら学習によって、LLMはテキストデータの細かなニュアンスも理解できるようになり、より自然かつ精度の高い自然言語処理を実現できます。
文脈を理解する
次は文脈を理解するステップで、入力されたテキストデータの文脈や背景を把握していきます。ここで重要になるのが「Self-Attention(自己注意機構)」と呼ばれる、各トークンが文章内のどこに位置し、どのトークンと密接に関連しているのかを自動的に計算する技術です。このSelf-AttentionによってLLMは、単語や文単体ではなく、文章全体の意味や文同士のつながりなどを理解できるようになります。
また、文脈理解を行うことで、たとえば「今がAIを勉強する絶好の機会だ」という文の「機会」を、マシンの「機械」ではなくチャンスの「機会」と判断するなど、同音異義語の使い分けも正しく理解することが可能です。結果として、LLMは人間のような理解力と表現力を獲得し、全体的に統一感のある文章を生成するなど、さまざまなタスクを実行できるようになります。
デコードする
最後のステップはデコードです。デコードとは、コンピューターが理解できるようにベクトル化していたデータを、人間が理解できる自然なテキストデータに変換する処理のことを指します。
このプロセスでは入力された情報に基づき、どのトークンが最も適切かを確率的に評価し、より自然な単語やフレーズを選択して文章を構築していきます。これにより、LLMは人間と円滑なコミュニケーションが取れるようになります。
以上のような流れでLLMは機能し、ユーザーが入力した質問や文章に対して適切に答えてくれるAIとして日々活用されています。
LLMのこれまでの歴史
LLMは、2017年にGoogle社の研究者らが「Attention Is All You Need(アテンションこそすべて)」という論文内で発表した、「Transformer」と呼ばれるディープラーニングモデルがきっかけとなって構築されました。そのためLLM自体の歴史は、関連技術であるニューラルネットワークや自然言語処理の歴史と比べると、それほど古くはありません。
Transformerは、従来の深層学習モデルよりも高速かつ高精度な自然言語処理を実現できるモデルで、言語モデルや自然言語処理の領域に革命をもたらしました。そのTransformerを活用したLLMはこれまでに数多く開発されてきましたが、中でもOpenAI社の「GPT」やGoogle社の「BERT」はLLMを代表する存在として、今もなお進化を続けています。
LLMの活用事例4選
LLMはその高い言語処理能力から、あらゆる場面で活用されています。ここでは、LLMの活用事例を4つご紹介します。
情報の検索・意味づけ
情報の検索・意味づけはLLMの最たる活用事例といえます。調査結果によって多少ばらつきはあるものの、ビジネスパーソンは社内情報の検索に平均1日1時間以上もの時間を費やしているといわれています。こういった状況を改善する方法としてLLMの活用はうってつけです。
たとえば、会議の議事録の情報を調べる場合、これまではファイルを開いて1つずつ何が書かれているかを確認する必要がありました。しかしLLMを活用すれば、検索をかけるだけで、その人が得たい議事録の情報を膨大なデータの中からピンポイントで取得することが可能です。
またLLMによっては、完全一致だけでなく近似一致を見つけることができる「ベクトル検索機能」を搭載しているものもあります。そのようなLLMを活用すれば、仮に資料の正式な名称が思い出せなくても、関連キーワードやプロジェクト名などを伝えるだけで必要な情報を抽出してくれます。
このようにLLMを活用することで、これまで情報の検索にかけていた時間を大幅に削減し、日々の仕事の生産性を向上させることが可能です。
広告・マーケティングのクリエーティブ制作
最近では、広告やマーケティングにおけるクリエーティブ制作も、LLMによって効率化できるようになってきています。いわゆるクリエーティブな作業というのは、従来はすべて人の手によって行われるのが当たり前でした。しかし、LLMをはじめとする生成AIの登場によって、その状況は変わりつつあります。
たとえば、あるサービスの広告文を考える際、サービス名やサービスの特長、ターゲットとなる顧客層、キャッチコピーなどをLLMに入力することで、そのサービスに適した広告文を出力してくれます。加えて、「3つ考えてください」などのプロンプトを入力することで、複数の広告文が出力され、どれが良いかを吟味することも可能です。もちろん最終的には人の目で判断し、多少の修正を加える必要があるものの、一からすべて人の手で行うよりははるかに効率的だといえます。
今回はテキスト生成に特化したLLMについてご紹介しましたが、画像や動画を生成できる生成AIも数多くあり、AIによってあらゆるクリエーティブ作業の効率化が進んでいます。ただし、LLMなどの生成AIによって生成されたものをそのまま商用利用すると著作権侵害にあたる恐れもあるため、その点に関しては慎重な取り扱いが必要です。
教育・学習支援
教育や学習と聞くと、学校や塾といった教育機関や、参考書などの書籍による学習を思い浮かべる人も多いのではないでしょうか。しかし最近では、LLMも教育・学習支援のツールとして活用され始めています。
学校や塾では各教科別に担当の教師が分かれているのが一般的で、参考書なども特定の分野に特化したものがほとんどです。そのため、理解できなかった箇所に関する補足説明や、さらに詳しく学びたいと感じた部分の追加情報などは、自ら聞きに行ったり探したりする必要がありました。
一方でLLMの場合は、個人の理解度やペースに合わせて、最適な情報を提供してくれます。自分に合った教材や資料をお勧めしてくれるほか、必要に応じて理解度に合わせた補足説明を聞いたり、問題演習を行ったりすることも可能です。さらには学習過程を通じて、興味がありそうなテーマや関連トピックなども提示してくれます。
LLMを教育や学習に活用するメリットは、教科や分野に捉われることなく、いつでも自分の好きなときに好きなだけ学べることです。近年の教師不足といった社会的な課題も相まって、新たな教育・学習支援のツールとして今後もLLMの活用の幅は広がっていくことが予想されます。
カスタマーサポートの効率化
質問に対する回答を得意としているLLMの特性を生かし、カスタマーサポートへの導入も進められています。主にカスタマーサポート用のチャットボットに組み込むかたちで導入され、すでにECサイトやWebサイト、アプリなどではLLMを組み込んだ24時間対応のチャットボットが普及し始めています。
カスタマーサポートへの問い合わせ手段として電話を採用しているところはまだまだ多くありますが、手段が電話しかない場合、24時間の対応が難しかったり、担当者によってサポートの質が変わってしまったりするという課題があります。そのような課題を解決する方法として活用されているのが、LLMを組み込んだチャットボットです。
チャットボットを導入することは、サービスの質の安定やオペレーションの効率化につながるほか、人件費や固定費を削減できるといったメリットもあります。また、LLMに対してファインチューニングなどの追加学習を行い、チャットボットの回答精度を上げることができれば、顧客の質問に対してより柔軟な対応が可能となり、結果として顧客満足度の向上も期待できます。
LLM(大規模言語モデル)の問題点
活用範囲が広く、非常に有用なLLM(大規模言語モデル)ですが、いくつか気をつけなければならない問題点や課題もあります。その中でも特に話題に上がることが多いのが、「ハルシネーション」と「プロンプトインジェクション」です。
・ハルシネーション ハルシネーションとは、LLMが事実に基づかない誤った情報や架空の内容を生成してしまう現象のことです。学習データとは異なる内容を出力する「Intrinsic Hallucinations」と、学習データに存在しない内容を出力する「Extrinsic Hallucinations」の2つがあります。ハルシネーションが発生してしまう原因としては、学習した情報が古いことや、LLM自体が情報の正誤を判断できないために誤った情報でも真実として扱ってしまうこと、学習データに偏りがあることなどさまざまです。
・プロンプトインジェクション プロンプトインジェクションは、悪意を持った第三者がプロンプトに介入することで、LLMの挙動や出力内容を意図的に操作する攻撃手法です。主にセキュリティ面での課題として挙げられ、企業の機密情報や個人情報などが漏洩するリスクがあります。
また、上記の2つに加え、生成AIの黎明期からいわれている「著作権や知的財産権の侵害」といった倫理的な問題についても併せて注意が必要です。
対策
上記のような問題が発生するのを防ぐには、総じてLLMに任せきりにせず、きちんと人間が介入することが非常に重要です。
ハルシネーションへの対策としては、「プロンプトエンジニアリングで回答の質を上げる」「ファインチューニングで情報の精度を上げる」「最後は人の目によるファクトチェックを行う」などが挙げられます。ハルシネーションは技術の発達とともに減っていくとも考えられていますが、それでも完全に防ぎきることは難しいとされるため、LLMを利用する際にはハルシネーションが発生する可能性を常に念頭に置いておく必要があります。
また、プロンプトインジェクションには「入力できるプロンプトを制限する」「出力結果をフィルタリングする」「運用ガイドラインを整備する」などの対策が考えられます。加えて、セキュリティに関する啓発を行い、ユーザー側のリテラシーを向上させることも効果的です。
著作権や知的財産権の侵害に関しては、「作品タイトルや作家名、具体的な登場人物の名前をプロンプトに含めないこと」などが有効的な対策といえます。
まとめ
今回はLLM(大規模言語モデル)についてご紹介しました。LLMは生成AIの一種であり、テキストデータの生成などの自然言語処理に特化したAIモデルです。その言語処理能力の高さから、マーケティングやカスタマーサポート、教育現場といったあらゆる場面で活用されています。
特に近年はLLMの進化が著しく、その有用性に注目されがちですが、一方で気をつけるべき問題点や課題も存在します。そのためLLMを上手に活用するためは、ユーザー側のリテラシーも併せて高めていくことが重要です。
関連リンク

